| 初识人工智能 | 您所在的位置:网站首页 › 11300 1135g7 5800h › 初识人工智能 |
初识人工智能
|
人工智能通俗理解(what):要让机器能像人一样甚至超过人去做一些事情。 怎么实现人工智能(how):使用人工神经网络技术。 神经网络与传统机器学习算法区别: 传统机器学习算法(线性回归,逻辑回归,决策树等)的内部过程已知(大型的复杂程序),神经网络内部过程未知(如人脑一样,不知道里面是怎么想的)。 神经网络构造图: 其中每一个⚪称为神经元,把神经元连接起来变形成了网络结构。该结构图形似人类的大脑结构。另一点,神经元的工作原理与大脑神经元的工作原理类似。 

神经元工作原理: 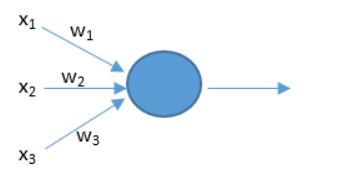
当神经元接收到输入x的刺激时,会有相应的输出,其中w的大小可以影响各个x对神经元的刺激强度。 注:在人工智能领域中,每一个输入到神经网络的数据都被叫做一个特征——上图中x1,x2,x3就是特征,把特征和在一起(x1,x2,x3)可以叫做特征向量。 神经网络如何预测: 最简单的公式:y = W·X+b,W是权重向量如(w1,w2,w3),X是特征向量如(x1,x2,x3)。b是偏执或阈值,可影响预测结果。y是预测结果。 如何判断预测结果: 损失函数(单个样本)有很多种,以下是比较创建的一个损失函数: 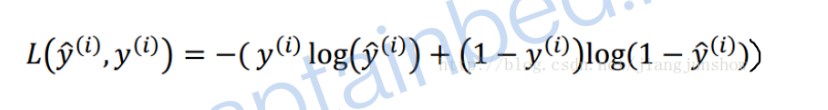
损失函数运算后得出的结果越大,那么预测就与实际结果的偏差越大,即预测精度越不高。努力使损失函数的值越小就是努力让预测的结果越准确。 反向传播:根据链式法则,对w和b各求偏导。 常见的激活函数: sigmoid,tanh,relu,leaky relu,softmax等。 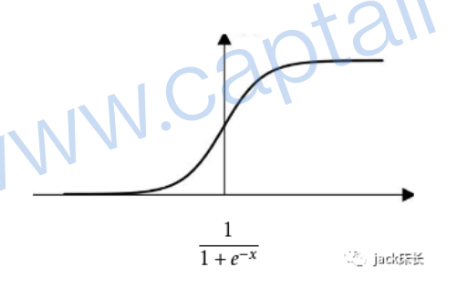
sigmoid:值域在(0,1)常用在二分类问题的输出层。缺点:该层的输入数据较大时,神经网络的学习速度比较慢。 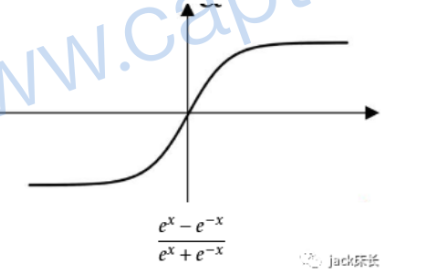
tanh:值域在(-1,1)它是sigmoid的升级版,在神经网络其他层中比sigmoid效果更好。缺点:该层的输入数据较大时,神经网络的学习速度比较慢。 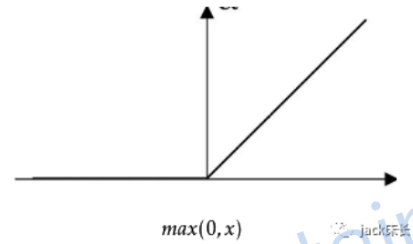
relu:神经网络学习速度较快,一般以它为首选激活函数。 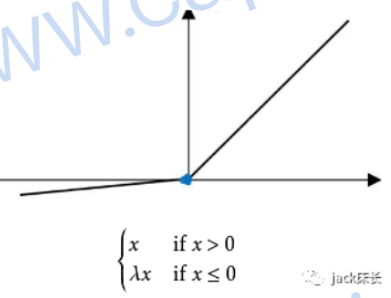
leaky relu:与relu类似,但是用较少。 提示:神经网络每层可以使用不同的激活函数,但一般根据项目实际情况,不会每层都是用不同的激活函数。 欠拟合与过拟合 欠拟合:在训练集的表现不好,在验证集上表现不好。 解决方向: ①增加神经网络的复杂度(增加层数,增加神经元);②增加训练次数;③更换优化算法;④更换神经网络架构 过拟合:在训练集的表现好,在验证集上表现不好。 解决方向: ①增加训练集(代价比较大);②正则化(l2正则,inverted dropout...);③更换神经网络架构 一般只有当模型过拟合了,才能使用正则化。 梯度消失与梯度爆炸: 梯度消失:偏导数极其小,导致神经网络更新非常慢。 梯度爆炸:偏导数极其大,导致参数数值大到超出计算机计算范围。 反向传播训练算法,不可避免梯度消失和爆炸,可以延缓(常见方法:初始化权重的数值更靠近0) mini-bach ,size一般是2的几次方。epoch表示对整个训练集进行梯度下降的次数。iteration表示梯度下降的次数。 动量梯度下降优点:①比标准梯度下降移动的快,②更容易走出局部最小。 RMSprop:通过调整平衡各个方向上的力,使梯度下降更快达到最小值点。 ADAM算法:它是动量梯度下降和RMSprop算法的结合 学习率衰减:分段常数衰减,一般指数衰减,自然指数衰减,多项式衰减,余弦衰减... 调参一般顺序:学习率,梯度下降算法相关参数,每层神经元个数,batch-size,神经网络层数,学习率衰减参数,其他参数。 利用线性标尺与指数标尺对超参数进行采样。 BatchNorm(隐藏层规范化):可以使隐藏层Z分布更稳定。 选择softmax回归还是logistic回归,可以参考类别时间是否独立;如独立择选softmax回归,反之选logistic回归。 使用tensorflow 1.X时,先设计在执行。tensorflow 2.X 三种构建模型的方式:Sequential model、Function API、Subclassing 优秀的监督学习型神经网络四大目标: ①在训练集表现足够好,②在验证集有好的表现,③在测试集有好的表现,④在实际应用中表现好。 模型优化原则:根据满足N个指标,然后去优化一个重要指标。 kaggle数据集:http: //www.kaggle.com/datasets 提升AI系统一般步骤: ①根据实际项目评估人类误差;②计算欠拟合误差与过拟合误差,并比较大小;③根据相应情况对欠拟合与过拟合进行处理。 一般过滤器(卷积核、filter)的大小为1X1,3X3,5X5....... 卷积计算公式: 3维卷积与一维卷积类似,即对应的三维分别进行一维卷积,然后累加。 1X1卷积(网中网):卷积核的高和宽都为一。 |
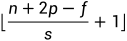 ,n为输入矩阵维度,p为padding,f滤波器维度,s为卷积步长,最后向下取整。
,n为输入矩阵维度,p为padding,f滤波器维度,s为卷积步长,最后向下取整。【本文地址】